.png)
How does the Knowledge Base work
-

- Andrea Sponziello
 31 July 2024
31 July 2024
Our Knowledge Base (KB) has two unique services that make it function:
- A parser - triggered when you upload a KB document.
- A retriever - triggered when your user asks a question that hits the KB.
Step-by-Step
You upload a KB Document to the parser service
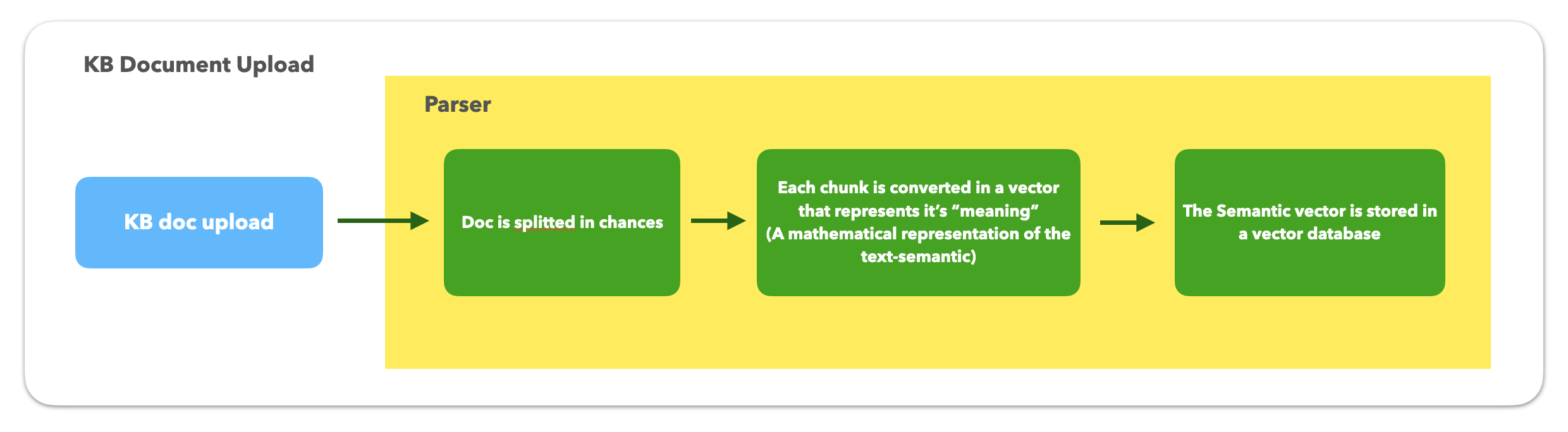
- The KB doc is uploaded via Tiledesk UI or API.
- The KB doc is securely stored. It is always removed in step [7]
- The Parser service reads the KB doc from storage and "chunks" the content using different techniques (Note: with the KB Upload APIs you can fine-tune chunking, but you cannot dictate how many chunks are parsed within a document).
- An embedding model is used to convert each chunk into a vector (aka “embedding”) that looks like a vector with i'ts numerical components [3.2, 2.13, ...] and represents its “meaning.”
- Computer programs don’t ‘understand’ spoken/written language as humans can. There needs to be a numerical representation of words to help programs understand. Each chunk from a KB doc is converted into a numerical representation (vector, aka “embedding”) of the MEANING behind the words in the chunk. More on why this is necessary in the Retriever section.
Note: Embedding models cost money to use, usually per token. The more files you upload, the more you are charged for embedding tokens.
In Tiledesk, we don't charge for the upload or embedding process. - The vector is placed in a vector db.
- The original KB doc is deleted from Tiledesk
You can think of this vector as a specific 'point” in “space.” All these points are some “distance” from each other, and the distance between two of these points (vectors) is how similar in meaning different chunks of text are.
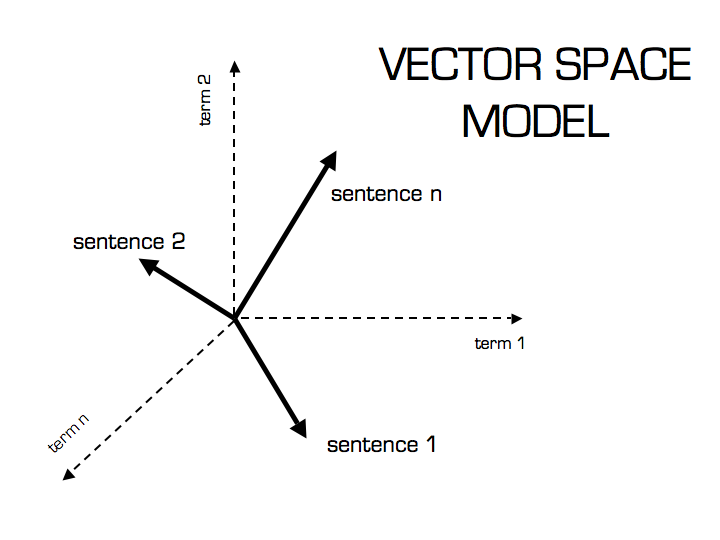
Image comes from this online artcile
User asks a question that hits the KB through the retriever service:
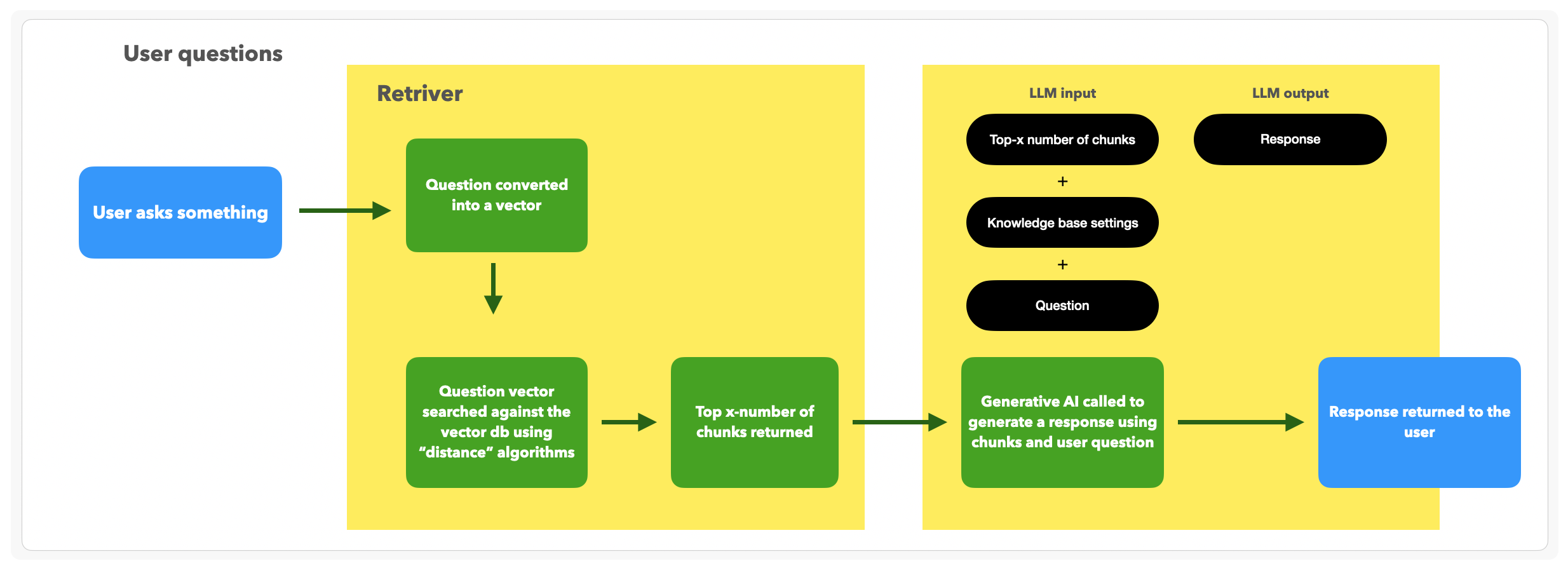
- The retriever service gets the question and turns it into a vector.
- The question vector is searched against the vectorDB by a similarity score, returning the most similar number of chunks (Chunk Limit defines how many chunks) in descending order by similarity score.
- Similarity score?
The similarity score is determined by something called semantic search. This goes beyond keyword matching and refers to contextual similarity in meaning between words and phrases. (i.e. “The dog is a nightmare to train.” and “The puppy is stubborn and does not listen to commands” do not share keywords. However, they have high similarity semantically.) So the question can be semantically compared to the KB doc chunks that exist. The “closest” vectors to the question are those with the highest similarity. The retriever will return a number of chunks (Chunk Limit in KB Settings) based on this vector proximity. - Chunk Limit?
Chunk Limit is the KB setting that controls the amount of chunks are retrieved from the vector db and used to synthesize the response. This setting aims to provide flexibility to increase the accuracy of responses in line with certain use cases.
How does the number of chunks retrieved affect the accuracy of the KB?
In theory, the more chunks retrieved - the more accurate the response, and the more tokens consumed. In reality, the "accuracy" tied to chunks is strongly associated with how the KB data sources are curated.
If the KB data sources are curated so that topics are grouped together, this should be more than enough to accurately answer the question. However, if information is scattered throughout many different KB data sources, then likely more chunks of smaller size will increase the accuracy of the response.
You can control the max chunk size of your data sources with the Upload/Replace KB doc APIs, using the query parameter: maxChunkSize.
Ultimately, in order to provide the best KB response 'accuracy' while optimizing token consumption, we recommend to limit the number of data sources and group topics inside those data sources.
- Similarity score?
Runtime Service:
- We take the:
- Returned chunks
- Knowledge Base Settings inputs
- Question
...and ask the LLM to give us an answer.
This step is called answer synthesis.
The internal prompts we use to iterate over time but are along the lines of, “using conversation history and user-provided instructions, answer the question sourcing information only found in Knowledge Base.”
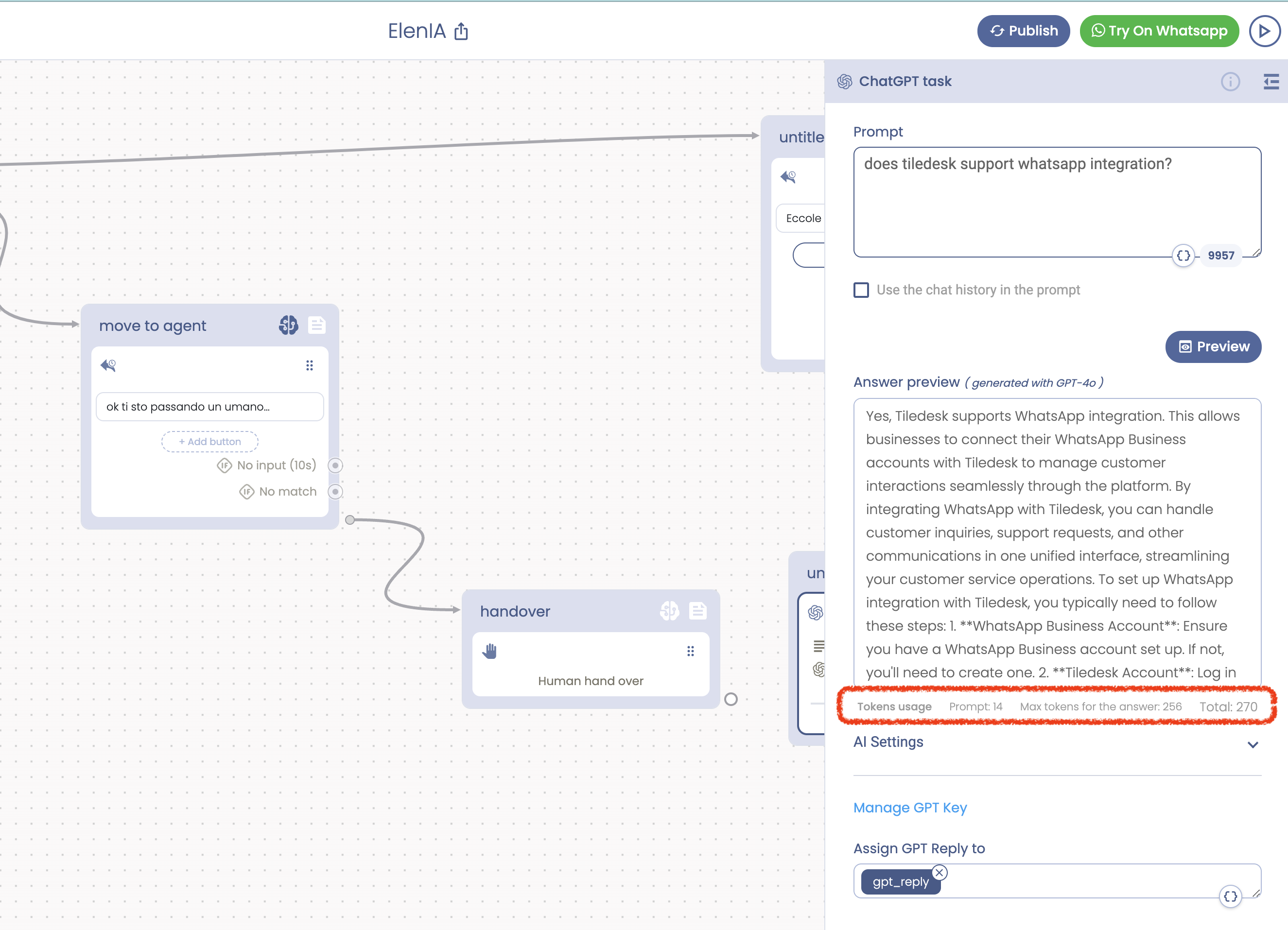
This LLM request has query and answer tokens that you are charged for. You can see these token totals in a response citation while testing in Debug mode on Tiledesk:
How your data is treated and secured
In Tiledesk Knowledge base data is processed through several key steps to ensure both functionality and security. Firstly, an embedding of a chunk of text (semantic vector) is generated by sending the content over HTTPS to an OpenAI service.
While OpenAI has access to the information during this phase, it does not store any data. Anyway keep in mind that if you have strict policies on your data there are alternative solutions. See lasta paragraph.
The generated vector is then stored in a Pinecone database, which ensures encryption at rest. The original text chunk is associated with its corresponding semantic vector within the Pinecone database.
When a user submits a query, it is also sent to OpenAI (without storage) to generate a semantic vector. This vector is used for proximity search in Pinecone, utilizing cosine distance alghoritm to find the most relevant matching chunks.
Finally the chunks coming out from the search are merged and passed to OpenAI to generate the final reply. This is another important step where your knowledge is used to feed an external service that anyway declares to never using your data.
In general, regarding the security of the original information, the semantic vector generation services are cloud-based for the basic service.
Enhanced data protection
For enhanced data protection, if you want to stay in the cloud, it is possible to
- Use Microsoft Azure services that implement OpenAI on dedicated, client-owned machines or
- Use an on-premises installation of the entire Tiledesk platform. This last setup can leverage open-source software like Chroma/LLAMA for embeddings and vector databases, ensuring that the information remains completely isolated from cloud services.